Amazon Image Rekognition
How it Works
Image Rekognition actions run in real-time, returning results within seconds and requiring no separate retrieval step. In this workflow, the DetectFaces API is first used to identify all faces present in an image. Each detected face then undergoes a preliminary filtering process to eliminate low-quality or irrelevant detections before proceeding with face matching.
For example, any face with a detection confidence score below 90% is skipped to reduce false positives, such as mistakenly recognizing unclear or blurry faces. The remaining high-confidence faces are then cropped from the original image and individually sent to the SearchFacesByImage API, which attempts to match them against your indexed face collection.
To optimize both accuracy and cost-efficiency, the plugin applies the filtering rules before calling the SearchFacesByImage API. These thresholds can be overridden by power users through advanced CatDV Worker properties, allowing experienced users to fine-tune the face matching behavior based on specific project needs or cost constraints. For more details, refer to the Advanced Properties section.
Import Worker Actions
While you're free to define your own workflows, pre-defined workflows are included in the WorkerActions folder to help you get started quickly. Simply drag and drop these files into the Worker GUI to import them. With minimal configuration, your workflow will be ready to use.
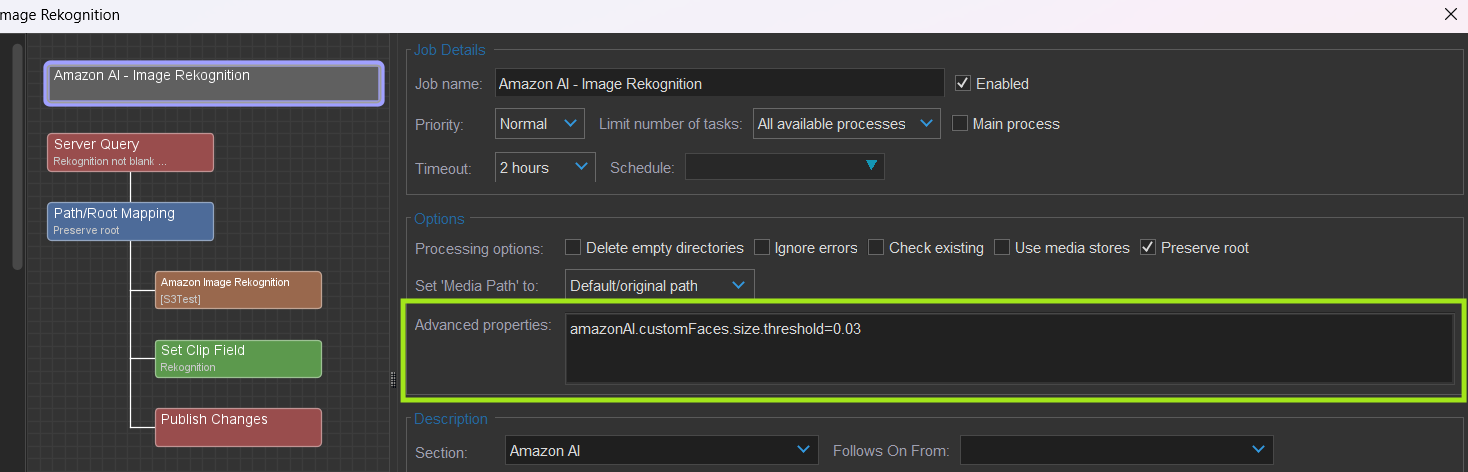
WorkerActions/Amazon AI – Image Rekognition.catdv
Worker Action Settings
The settings available in the Worker Plugin are:
S3 Volume | The S3 remote volume identifier is required to access the S3 bucket. If you haven't set up a remote volume yet, please refer to the Authentication section. Note: The identifier must be enclosed in square brackets []. |
AWS Access Key (optional) | Define only if you wish to use a different account to perform the operation. |
AWS Secret Key (required) | Used as part of the authentication. |
Set Parameters | Define the request parameters using CatDV fields or set them manually on the worker. |
Detection Types | Specifies what Amazon Rekognition looks for in an image—such as objects, faces, text, or unsafe content—to generate useful metadata for tagging and analysis. Label: Detects objects, scenes, and concepts in the image (e.g., car, tree, wedding). Faces: Detects faces and facial attributes like age range, emotions, or gender. Celebrities: Identifies well-known people in the image using Amazon’s celebrity database. Text: Detects and extracts text from images (printed or handwritten). Unsafe Images: Flags potentially inappropriate or unsafe content (e.g., nudity or violence). Custom Faces: Matches detected faces against a custom face collection you’ve indexed. See Index Faces. |
Minimum Confidence | Sets the threshold (0–100) to filter results based on Amazon Rekognition's confidence score. Note that Label and Unsafe Image detection types have default confidence thresholds set by Amazon—55 for Label and 50 for Unsafe Image. If you wish to receive results below these defaults, you can specify your own minimum confidence value. |
Show Confidence in Marker Name | Set confidence score as Marker name. e.g. ‘Confidence 83.55’ |
Detect Text by | Only applicable to detection type “Text” · Line – Read full sentences or lines of text as they appear together in the image (like a sentence on a sign). · Word – looks at each individual word separately, even if they’re part of a longer sentence. |
Draw Bounding Boxes | Only applicable to Custom Face detection. Highlights detected faces with rectangular overlays. Note: A bounding box color must be specified for this feature to be applied. |
Bounding Box Colour | Specifies the color used to draw rectangles around detected custom faces in the image. |
Output Field | The CatDV field where the Amazon Rekognition results will be saved. This field can be reused for different detection types, and the results will be appended. |
Output as | Nicely-formatted HTML or Plain Text. |
Include Headings | Displays a header before the Rekognition results. This is useful when running multiple detections on the same clip, as the header helps segment the results for better organization. Below are headings that use for respective detection type Label: Detected Labels Faces: Detected Faces Celebrity: Celebrities Text: Detected Text Unsafe Image: Unsafe Images Custom Face: Custom Face |
Advanced Properties
For system builders and power users, here are some additional plugin options which can be set in the Worker Node Advanced Properties box:
Property key | Valid range (default) | Description |
amazonAI.outputRawResponseDataToField | <field identifer> | Writes a JSON object to the field of your choosing e.g. clip[ai.json] - note these responses can be half a megabyte or larger which doesn’t sound like much but can crowd your database if you’re not careful, so it is recommended only to use this feature in a transient nature and then remove the extra data when finished. |
amazonAI.outputRawResponseDataToFile | <path> | Writes a JSON object to an external text file of your choosing (e.g. /Volumes/MyData/myResponse.txt) which you could parse separately and then toss away, rather than keeping all of the raw response data in the CatDV database. |
amazonAI.customFaces.confidence.threshold | 0 to 100 (90) | Only applicable to “Custom Faces” action. The confidence score returned by the DetectFaces API must meet a minimum threshold to confirm that a face has been detected. |
amazonAI.customFaces.yaw.threshold | -90 to 90 (40) | Only applicable to “Custom Faces” action. Yaw represents the rotation of the head left or right. 0° is facing directly forward. -90° represents a full left turn (side profile). 90° represents a full right turn (side profile). The default yaw threshold ≤ 40°: This would allow faces that are rotated at most 40° to the left or right of the center (still relatively front-facing). |
amazonAI.customFaces.pitch.threshold | -90 to 90 (30) | Only applicable to “Custom Faces” action. Pitch refers to the up and down rotation of the head. In other words, it's the tilt of the head. A positive pitch value represents the head tilting upwards (looking up), and a negative value represents the head tilting downwards (looking down). · 0° is the neutral, level position of the head. · -90° means the face is tilted downward (looking at the floor). · 90° means the face is tilted upward (looking at the ceiling). The default pitch threshold ≤ 30°: This would allow faces with a tilt of up to 30° either up or down from the neutral position. |
amazonAI.customFaces.roll.threshold | -180 to 180 (30) | Only applicable to “Custom Faces” action. Roll refers to the tilt of the head sideways—like when someone leans their head toward their shoulder. It measures how much the face is rotated along the axis that runs through the nose. · 0° means the head is upright. · Positive values indicate tilting the head to the right (their right). · Negative values indicate tilting the head to the left (their left). The default roll threshold ≤ 30°: This allows faces with a sideways tilt (head leaning left or right) of up to 30° from the upright position. Faces tilted more than this may be excluded to ensure better recognition accuracy. |
amazonAI.customFaces.sharpness.threshold | 0 to 100 (5) | Only applicable to “Custom Faces” action. Indicates how clear and focused the face is. · 0 means very blurry. · 100 means very sharp and detailed. |
amazonAI.customFaces.brightness.threshold | 0 to 100 (20) | Only applicable to “Custom Faces” action. Indicates how well-lit the face is. 0 means very dark. 100 means very bright. |
amazonAI.customFaces.size.threshold | 0.001 to 100 (0.03) | Only applicable to “Custom Faces” action. The face area threshold is expressed as a percentage of the total image area. It determines the minimum size a detected face must be—relative to the whole image—to be considered for custom face matching. 0.001% = extremely small faces (e.g. tiny faces in the background) 100% = the face takes up the entire image (not practical for real use) In practice, values between 0.01% and 1% are reasonable, depending on your use case. |
amazonAI.debug | true/false (false) | Only applicable to “Custom Faces” action. Logs the full Amazon API response. Useful for debugging purposes. Do not enable unless needed, as the response can be very large. |
Best Practices
Using Amazon Rekognition’s Custom Face Detection with CatDV Worker automation can become costly if not managed carefully. Each face in the image that passes the 90% detection confidence threshold is cropped and sent to the SearchFacesByImage API to attempt a custom face match. Since you are billed per SearchFacesByImage request, the cost can add up quickly when processing images with many faces.
Below are some recommended best practices to help you maintain control over potential costs.
1. Apply Custom Face Detection Only to Relevant Images
Avoid running custom face detection on every image in your CatDV library. Instead, selectively apply it to images or clips where face matching provides significant value. For general object detection, use Label detection or Faces detection, which are less costly.
2. Filter Images Before Running Rekognition
Use metadata, picklists, or other filtering options to limit the images being processed. This ensures you’re not triggering face detection on unnecessary images. Only process images that you are certain need custom face recognition.
3. Batch Process Images Efficiently
Instead of running detection continuously, batch process images during set intervals (e.g., once every hour, day, or after specific content additions). This helps avoid redundant processing and provides cost efficiency.
4. Monitor and Analyze Costs Regularly
Track your Amazon Rekognition usage through AWS Cost Explorer or other reporting tools to monitor the costs of your face detection operations. If costs begin to rise unexpectedly, review your settings and adjust workflows as needed.
Usage Cost
With Amazon Rekognition Image, you only pay for what you use. There is no up-front commitment or minimum fee.
Amazon AI USD pricing as of Summer 2020 is:
12 months free - 5000 images per month
then $0.001 per image (further discounts for more than 1 million images / month)
More recent pricing is determined based on the specific API operations you use, which are categorized into different groups.
Image Rekognition Action In CatDV | Amazon Rekognition image APIs which action called |
Label | Group2: DetectLabels |
Faces | Group2: DetectFaces |
Celebrities | Group2: RecognizeCelebrities |
Text | Group2: DetectText |
Unsafe Images | Group2: DetectModerationLabels |
Custom Faces | Group2: DetectFaces and Group1: SearchFacesbyImage |
For latest pricing information refer to Amazon official site https://aws.amazon.com/rekognition/pricing/ .
Please be mindful of the AWS service costs associated with each AI operation, especially as you scale up usage of the plugin. Quantum Corp. does not accept any liability for AWS service costs incurred as a result of using this software, regardless of if the usage incurred was intentional or not.