Whisper Transcribe
Things to Keep in Mind When Using Whisper:
If you are using Whisper for the first time, ensure you have internet connection so the model can download and install correctly.
Performance may vary significantly depending on the language being transcribed. For more info on the available models and languages, visit https://github.com/openai/whisper?tab=readme-ov-file#available-models-and-languages
Performance also depends on the Whisper model selected, as different models offer varying levels of speed and accuracy.
Whisper only supports translation from various languages into English.
· Some users have reported that the Turbo model does not perform well with translation tasks (https://github.com/openai/whisper/discussions/2363#discussioncomment-10816342), possibly due to its design focusing on speed over complex functionalities like translation, and since it isn’t trained on translation data, you’ll need to choose another multilingual Whisper model (like tiny, base, small, medium, or large) for better performance.
Transcription and translation quality will be influenced by factors such as audio clarity and context.
The CatDV Whisper plugin uses GPU acceleration on Windows for faster transcription and translation. If no compatible GPU is available, it automatically switches to CPU mode to ensure smooth operation.
GPU Support Notice
Windows: Whisper supports GPU acceleration via CUDA when using a compatible NVIDIA GPU. You can choose the version WhisperAI_Win_GPU.catdv to if you have a graphics card.
macOS: GPU acceleration is not supported now due to PyTorch’s limited support for Metal Performance Shaders (MPS). While MPS is still in beta, active development is underway to improve its stability and performance. Until full support is available, Whisper runs exclusively on the CPU on macOS.
Worker Action Settings
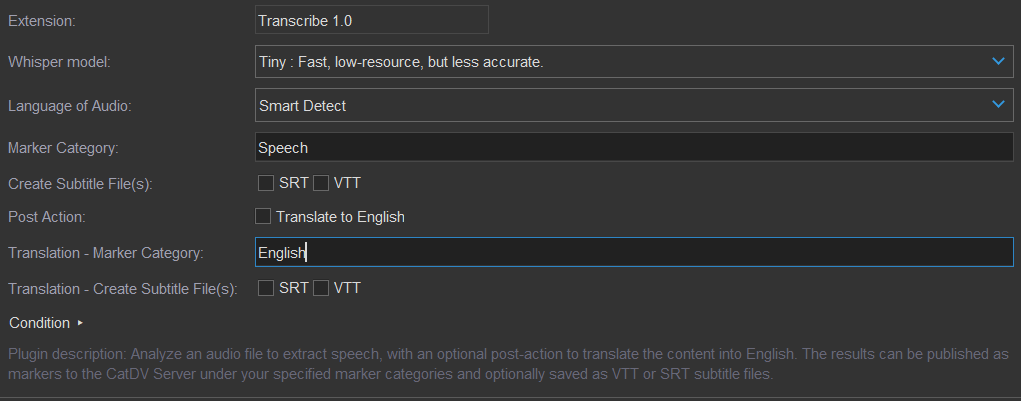
The settings available in the Worker Plugin are:
Model | Let you choose the transcription model to use, with options offering a balance between speed and accuracy. Tiny: Fast, low-resource, but less accurate. Base: Balanced speed and accuracy, good for most tasks. Small: More accurate, moderate speed. Medium: Accurate, slower processing, requires ~5GB VRAM. Large: Most accurate, slow and high-resource, requires ~10GB VRAM. Turbo: Fast and accurate, optimized for large workloads, requires ~6GB VRAM. |
Language | Specify the source/spoken language. While Whisper can detect the language automatically, specifying it can help achieve faster, more accurate, and reliable translations, particularly in complex or noisy scenarios. |
Marker Category | Allows you to define the marker category where the transcript will be published on the CatDV server. |
Create Subtitle File(s) | Allows you to create a subtitle file as a sidecar for the transcription output. You can choose to generate an SRT or VTT file or leave the option unchecked if you do not wish to create a subtitle file. |
Post Action | Translate to English – Translates the transcribed audio into English. Note: If you don’t enable “Translation” initially, enabling it later and resubmitting the clip will cause the job to redo “Transcription”. |
Translation - Marker Category | Allows you to define the marker category where the translation will be published on the CatDV server. |
Translation - Create Subtitle File(s) | Allows you to create a subtitle file as a sidecar for the translation output. You can choose to generate an _en.SRT or _en.VTT file or leave the option unchecked if you do not wish to create a subtitle file. |